|
|
What is XPATH? |
|
|
What is XPATH? |
The primary purpose of XPath is to address parts of an XML document. It also provides basic facilities for manipulation of strings, numbers and booleans. XPath uses a compact, non-XML syntax to facilitate use of XPath within URIs and XML attribute values. XPath operates on the abstract, logical structure of an XML document, rather than its surface syntax. XPath gets its name from its use of a path notation as in URLs for navigating through the hierarchical structure of an XML document.
In addition to its use for addressing, XPath is also designed so that it has a natural subset that can be used for matching (testing whether or not a node matches a pattern); this is why it is used in Alchemy CATALYST to check for conditions within a document.
XPath models an XML document as a tree of nodes. XPath defines a way to compute a string-value for each type of node.
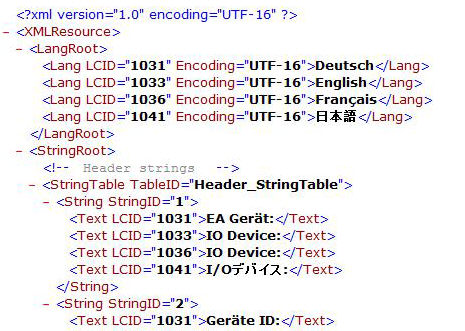
In the example above there is an element called Lang which has attributes LCID and Encoding. Using XPath we can check the value of LCID by using the following syntax: @LCID="1033". This will check the value of LCID and compare it to the value of 1033. If the value of LCID equals 1033 the condition is said to be True otherwise it is False.
Combining the power of XPath with ezParse it is now possible to include/exclude sections of XML documents depending on defined conditions. This make it possible to support multi-lingual XML documents or large complex documents that originate from content management systems (CMS).
| (c) Copyright Alchemy Software Development Ltd. |