|
|
Segmentation Rules |
|
|
Segmentation Rules |
Segmentation refers to the rules used to break a paragraph into individual sentences. Segmentation rules can vary from language to language. While a full-stop may be an indicator of a sentence terminator in English and German paragraphs for example, it is not so in Japanese. Alchemy CATALYST has predefined segmentation rules, but these can be replaced and modified in this dialog.
Using Sentence based parsing, Alchemy CATALYST will apply the matching language segmentation rules and detect sentence boundaries when inserting a file (i.e. parsing the file) in the project.
This is the most accurate way of building TMs as translation units will generally consist of single sentences. This mode thus produces more accurate TM re-use and discovery.
|
|
Take the following example. A source project file includes the following localizable string: String_ID251=The cat is black. He is sleeping on the chair. He slept for two hours already! Using the Sentence based segmentation, on inserting the file in a CATALYST project, the string list view will look like this
while using the Paragraph based segmentation, the string list view will show
Let's assume this is now translated in your TTK project. The source file is then updated with a small change. The string is updated to: (the difference is highlighted in yellow) String_ID251=The cat is black. He is sleeping on the sofa. He slept for two hours already! Using Sentence based segmentation will have far less of an impact because leveraging your translations will result in one string needing to be reviewed in project parsed
while the entire paragraph needs to be reviewed when not segmenting
|
As per the example above, when leveraging translations from TMs that are not directly related to the current project files, there will be more high percentage matches when comparing individual sentences rather than full paragraphs.
Configuring segmentation delimiters
By default, rules listed under Language Neutral will apply to ALL files parsed into your projects, regardless of the source language set. You can Add a language to the dropdown and set different segmentation rules applicable to that language only. Those rules will only apply to projects with the matching source language.
A Sentence delimiter is the syntax which when found within a parsed localizable string triggers the segmentation. Meaning will section a paragraph string into mutliple sentences.
The basic segmentation rule in most languages is for instance a full stop followed by a space, indicating the end of a sentence. Here it is entered below, and part of the default rules in CATALYST.
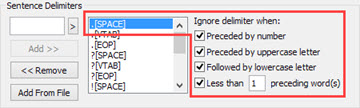
The delimiter can be refined further using the Ignore options associated. If you think of a sentence with an person's initial, the delimiter alone without the "Ignore when preceded by uppercase letter" would segment in the wrong place.
The book was written by J. Doe. He is a great novelist. <= Wrong segmentation
|
|
Segmentation rules are only applied to specific file type groups in the ezParse rules. Currently these include:
For all other file groups it is far more efficient to store each string as a single segment in the TM. |
Handling Segmentation Exceptions
Abbreviated words or anagrams may occasionally cause the segmentation engine to misinterpret a sentence boundary. This can be avoided by specifying any sequence of characters that are to be ignored when applying segmentation rules.
In the same way specific syntax can be entered to trigger a segmentation, syntax can be entered to avoid the segmentation.
In this mode, Alchemy CATALYST will ignore sentence boundaries and store complete paragraph objects in its TM. This may be useful when aligning two translations that have significant differences in structure and format.